
Why Is the Dev & Data Tech Stack So Darn Complicated? (IV/IV)
The future of dev & data - will the dev & data stack continue to develop into a Rube Goldberg machine?


The ‘best-of-breed’ vs. the ‘all-in-one’ vs. ‘the glue’
Early-stage venture investing sometimes feels a bit like looking into the crystal ball and a lot of fellow investors also like to make bold predictions about future developments, trends, etc. - and some happen to actually be very good at it. So I will try my luck with it here as well.

The big question I was asking myself is if the continued fragmentation in both the dev and the data stack that we have seen so far is going to continue. It already feels overwhelming now but when will we reach the point where even the most sophisticated devs after years of education and practice cannot cope with the vast majority of tools available or necessary anymore? So do we really need more specialization and consequently more complexity?
🔮 The answer is: yes and no.
I believe we will see three different drifts happening at the same time. Two of them will actually be opposing trends:
🐂 The best-of-breeds: even more narrow and niche best-of-breed solutions for sophisticated and specialized dev & data workers on the one hand,
vs.
📦 The all-in-ones: high-level of abstraction, unified solutions that offer 80% of the functionality of a whole stack of tools at 20% of the complexity, thus allowing a single more or less technical person to use it.
Let’s look at concrete examples in the data stack to make it more tangible.
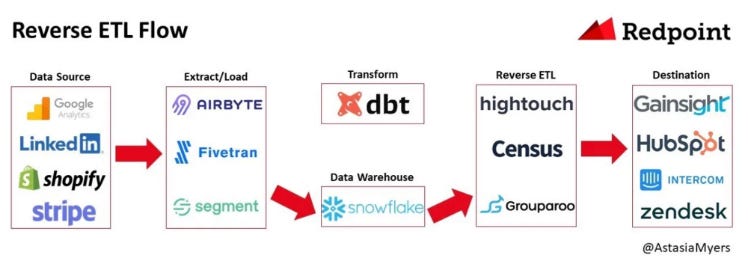
The concept of reverse ETL tools (such as Census, Hightouch, Grouparoo) can do pretty much one thing, and that one thing they can do very good. They enable businesses to extract data from their data warehouse, transform it into a format that can be consumed by other applications, and then load it into those applications (as very well described by Astasia Myers on her Medium. That’s it. Very specialized

Let’s just call them ‘Modern-data-stack-as-a-Service’ players (such as Y42, Weld, Kleene). These companies pretty much cover the whole data value chain from ETL/ELT, to data modeling, data orchestration, over data storage, to reverse ETL and even BI or ML capabilities. This is a lot of functionality in one tool. At the same time, some of them are not only addressed to data engineers or data analysts, but also to less technical and more business-oriented user groups. They can only do so by abstracting away a lot of the underlying complexity and infrastructure. But what if you want to use Fivetran instead of Airbyte? Nevertheless, a very holistic offering

Image: Y42 website

Similar things can, again, be said about the dev stack where e.g. Backend-as-a-Service (BaaS) solutions (such as Supabase, Firebase) abstract away a lot of the pain of setting up and maintaining a back-end at the same time where teams are for example building very narrow products that are just focused on e.g. improving the performance (ito. speed, cost) of a database. And please do not get me wrong, I truly believe there is value in both approaches and that both are needed going forward.
Even though we can already observe these diverging trends I believe there will be a radically higher level of abstraction on both, i) the ‘middle-layer’ of a stack, i.e. bundling functionality from a couple of different similar and adjacent tools, as well as ii) the whole stack in which you basically get all you need to build an E2E running application out of one hand, in a solution that is low-to-zero config but delivers an output that is at least good enough for many project’s requirements and can even come close to what could have been built with a more fragmented tool stack.
We have talked about 2 rather extreme evolutions so far. I now also want to make a case for a third development, a middle-ground or, maybe, a compromise between the other two.
I want to call this segment:
🩹 “The Glue”. These tools will be a fixative holding together several of the more specialized best-of-breed solutions. I am not yet sure how these solutions will form exactly, but I imagine it to be a (visual?) interface that easily lets you build, spin up, and maintain the stack of your choice in an automated fashion. Just like a virtual tech architect assistant. It will handle building the bridges between these isolated tools, make sure they neatly integrate and communicate with each other, and that processes running through the “value chain” of your stack do so in the right schedule and without breaking. And they will combine a lot of the advantages from both of the extremes:
Flexibility/freedom: just like putting together your own best-of-breed stack, you can choose the tools that you know, that you love, and that you want to continue to use
Power & scalability: since the underlying tools are made to build high-performing applications, they’ll meet your requirements for even the most complex project requirements
Centralized access point: no need to actually go into all the underlying parts of the stack; you have a single access point that is like a meta layer orchestrating the underlying components
Ease of use: you don’t get lost in the details as the platform will handle most of the config for you (unless you want to)
Again, I do see the cases for all three of these developments in parallel. It is just a matter of fit and ICP what users will go with what solution in the end, depending on their needs & preferences.
This brings me to the end of my small series on ‘Why the dev & data tech stack so darn complicated?’. I hope you enjoyed joining this journey from i) the status quo of the dev & data stack to ii) where this complexity came from, over iii) how to think about compiling your own stack to iv) a little outlook on potential developments. As this was so far a more one-directional messaging channel with me sharing my thoughts that were shaped by own experience, from talking to many dev & data founders, but also input and feedback from accomplished CTOs, CPOs, and data scientists, I would be more than happy to also receive your feedback and input - so please message me and get in contact. Additionally, if you are a founder also working on either building the next category within the dev or data stack or drastically simplifying it, we should also talk.
In a next step, I will look into individual parts and trends within the dev & data stack in more detail but also draw the line to the commercial aspects of operating a B2D company and selling a B2D product. So stay tuned :)